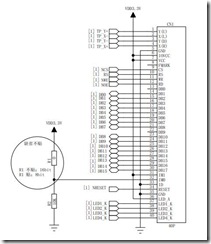
无刷直流电机正反转过零点换相
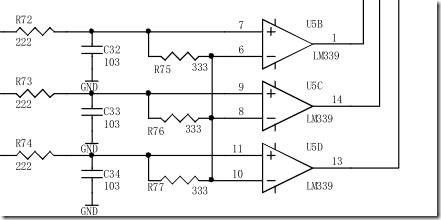
无刷无感直流电机换向时一般采用反电动势过零点的办法,ABC三相端电压经低通滤波器后,求和得出模拟中性点,滤波后的端电压再与模拟中性点电压比较得到过零点。过零点检测电路如下,R72,...
运放测电路电流
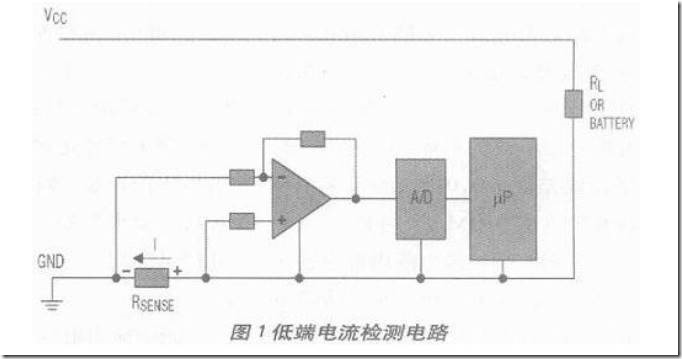
电流检测方案一般分低端电流检测和高端电流检测。低端电流检测的检流电阻串联到地,高端电流检测的检流电阻串联到高电压端。下图是低端电流检测电路示意图:低端检测电路抬高了地电压,不如高端...
PID算法控制马达转速
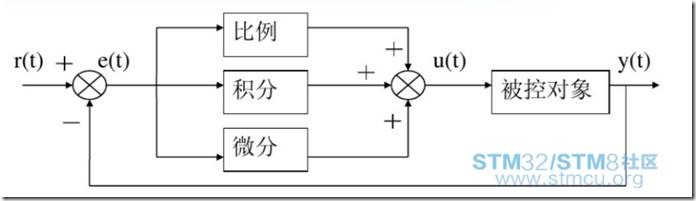
PID算法听起来高大上,理解后实际上是很简单的,实现代码也很小。PID控制是将实际值与目标值的偏差的比例(P),积分(I),微分(D)的线性组合作为控制量,控制被控对象。PID控制...
MDK 出现#68-D: integer conversion resulted in a change of sign(转)
在KeilARM的LPCARM,存在(1<<31)编译警告问题main.c(174): warning: #61-D: integer operation result...
keil5 编译程序出现错误Error: L6411E: No compatible library exists with a definition of startup symbol __main(转)
Error: L6411E: No compatible library exists with a definition of startup symbol __main.之前装...
CH372实现HID键盘功能
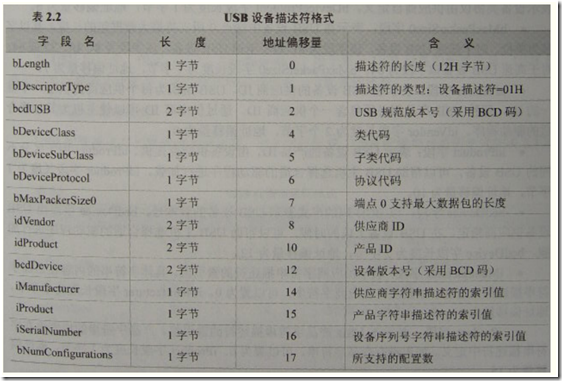
有些IC发卡器在刷卡时,卡号可以填写在文档光标处。这种产品很多年前就有了,最近刚好有客户有这方面需求,用CH372做了一款HID键盘类型的发卡器。 一款HID设备包括设备描述符,...
LPC1768 内部RTC程序
typedef struct{ uint8_t RTC_Sec; uint8_t RTC_Min; uint8_t RTC_Hour; uint8_t RTC_Mday; uint...
LPC1768读写W25Q128程序
uint8_t W25QXX_Buf[4096]; GPIO设置 /*SPI pin set*/ PinCfg.Funcnum = PINSEL_FUNC_3; PinCfg.Po...
TCP相关知识
1、 三次握手过程最后一个数据包丢失 当Client端收到Server的SYN+ACK应答后,其状态变为ESTABLISHED,并发送ACK包给Server,如果此时ACK在网络中...
以太网帧结构
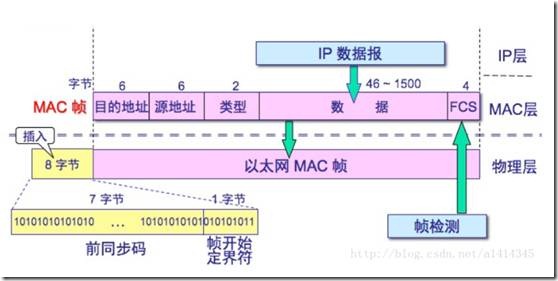
帧结构图: 前同步码和帧开始定界符:一个帧以7个字节的前导码和1个字节的帧开始符作为帧的开始。在线路上帧的这部分的位模式是10101010 10101010 10101010 1...
TCP连接过程解析
TCP客户端和服务器之间建立连接的过程称为3次握手过程。握手过程由客户端程序首先发起,整个过程要经历下面3个步骤: 1、客户端发送一个SYN标志置1的TCP报文段,报文段首部指明自...
CPU卡电子钱包圈存与消费(三)

三、 消费 1、选择3F01目录 Send Data : 00 A4 00 00 02 3F 01 RSP[88]: 6F 54 84 09 A0 00 00 00 03 86 9...